
The Billion-Dollar Bet on Voice + Vision Search (And Why Most SEO Teams Will Miss It)
Meta, Google, and OpenAI poured billions into cameras that see, voice that understands, and agents that act. Your keyword strategy won't survive it.


A few weeks back, I watched someone point their phone at a menu and ask out loud: “What’s the healthiest dish here for a Type-2 Diabetic?”
No typing. No website visit. Just an answer in seconds.
That was my first real encounter with voice+vision search in the wild. And here’s what hit me: this isn’t some 2030 concept we get to plan for. It’s shipping now inside Google AI Mode, ChatGPT’s multimodal interface, Meta’s Ray-Ban glasses, and the next wave of smart wearables and appliances coming in 2026.
The shift is brutal in its simplicity: your surroundings become the search box.
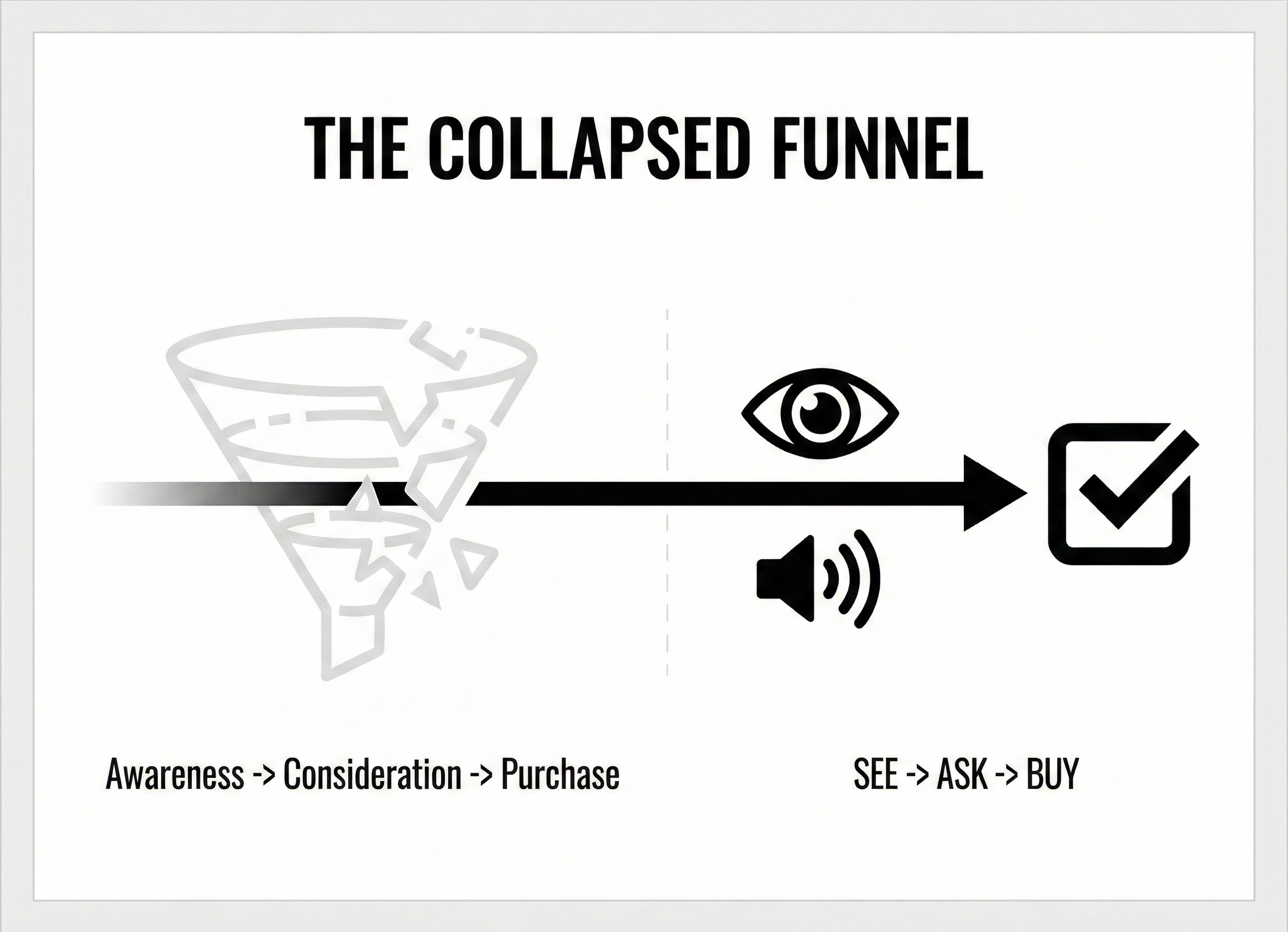
Walking down the street? See shoes you like. Point. Ask. Get alternatives under your budget. The funnel just collapsed from Awareness → Consideration → Purchase to See → Ask → Buy.
If you’re still building SEO strategies around keyword tools and SERP features, you’re optimizing for a world that’s already fading. Let me show you what’s actually happening right now.
The Technology Is Live, Not Coming
Google’s AI Mode accepts voice and image inputs together. You can upload a photo, ask a question about it, and get a structured answer powered by Gemini. Their “Live Search” feature goes further—share your camera feed in real time and ask questions about what you’re looking at.
This is production software. Millions of users are interacting with it today.
Meta’s Ray-Ban glasses already let you look at an object and ask a question. The AI sees what you see, hears what you say, and responds. No screen. No typing. Just existence + curiosity.
OpenAI’s multimodal models combine text, image, and voice in a single interface. You can send a picture, describe what you want to know about it through speech, and get synthesis across formats.
The foundation isn’t theoretical anymore. It’s deployed.
The Money Trail Tells the Real Story
If you really want to know where the world is going, look at who’s writing the cheques.
The venture world has quietly moved billions into technologies that sit exactly at the intersection of voice, vision, and real-world AI interaction.
Not hype cycles. Not speculative research. But companies building the hardware and software that make “point and ask” the default interface of daily life.
Humane AI Pin raised over $230M to build a screenless AI assistant - a wearable device with a camera, voice interface, and no display. The product struggled, but the funding signal is clear: investors believe a camera+voice+AI stack will replace chunks of how we search.
Brilliant Labs pulled in $6M+ to build glasses where “the camera is the new cursor.” You look. The AI understands. An agent responds. They’re not building AR for gaming—they’re building AR for knowing.
Rewind (now Limitless) raised $10M for a wearable pendant that records your day, then becomes a searchable archive of your lived experience, an extended memory.
Meta has poured tens of millions into glasses that see, hear, and interpret context. Their Ray-Ban Meta glasses are the first consumer-grade multimodal search device in the real world. And it’s not tech obsessives using them—it’s regular people.
Rabbit raised $30M to build voice-first agentic interfaces. Right now it’s audio-only, but their roadmap is obvious: cameras are coming, multimodal understanding is coming, real-world context is coming.
Luma AI raised $900M+ to teach models how to understand 3D spaces, not just flat images. If you want a computer to answer questions about the real world, it has to perceive the real world as objects, shapes, and context.
Then there are the appliance giants like Samsung, LG, Bosch, Dyson are quietly embedding cameras, sensors, and voice modules into ovens, washing machines, and refrigerators.
The Pattern Behind All This Money
Zoom out and every one of these bets lands in the same place: a three-layer stack that lets machines perceive the world, understand what you want, and act on it.
Layer 1: Devices that see
(glasses, appliances, 3D capture, cameras everywhere)
Layer 2: Models that understand
(multimodal AI, computer vision, speech models)
Layer 3: Agents that act
(Anthropic Agents, OpenAI agents, Google Gemini ecosystem)
Perception. Understanding. Execution. That’s the full stack for voice+vision search. VCs are funding the infrastructure that replaces the search landscape.
You may ask, Is that a search?
Of course it is. It’s a search without browser.
What This Actually Means for SEO
When search becomes something that happens through voice and vision, the relationship between “website → search engine → user” breaks. There’s a new middle layer now: the AI agent. And it behaves very differently from a human visitor.
Agents don’t browse. They don’t scroll. They don’t skim your hero section to get the vibe. They extract. They compare. They decide.
That forces SEO into a new shape.
1. Your Data Becomes the Real Homepage
In this world, the first impression of your brand doesn’t come from your homepage design. It comes from your data.
An agent doesn’t zoom out to admire your layout. It goes straight into the bones of your information: the numbers, the specifications, the metadata, the ingredients, the labels, the reviews, the structured facts.
Because an agent has one job: don’t get the user the wrong answer.
So it needs your data to be clean, unambiguous, and machine-readable. In a world of voice+vision search, your content isn’t what introduces your brand. Your clarity does.
2. Your Brand Becomes the Ranking Signal
When queries become conversational and contextual, keywords lose power.
A camera feed and a spoken question don’t translate neatly into “best walking shoes for a 60yr old man suffering with arthritis.” They translate into: “Who can I trust to answer this correctly?”
That’s not a keyword question. It’s an entity question.
Search engines, and now agents are no longer matching text. They’re evaluating identity:
Is this brand who it claims to be?
Is its information consistent everywhere?
Do trusted sources talk about it?
Does it have a clear footprint across the web?
It’s the quiet shift from “optimizing pages” to strengthening your presence as an entity.
3. Trust and Structure Become the New Moat
The more machines participate in the search-and-recommend process, the more the cost of being wrong increases. And when the cost of being wrong increases, the bar for recommendation rises.
This is why in the voice+vision era:
Accuracy beats cleverness
Structure beats style
Consistency beats volume
Truth beats theatrics
It’s not that creativity dies but it’s alone can’t carry you anymore.
Agents need to be confident that your data is correct, not just roughly correct, not “good enough to get the click,” but reliably true. The brands that can offer that level of clarity will be chosen again and again.
The Quiet Evolution of SEO
When you put these three shifts together: Data as the homepage, entities over keywords, trust as the moat—you end up with a new definition of SEO:
SEO becomes the discipline of making your brand the safest, clearest, most defensible answer a machine can recommend.
Not the most optimized page. Not the most articles. Not the largest keyword cluster footprint.
Just the most answerable brand, and that is where the next decade of organic visibility begins.
What Happens Next
We’re stepping into a world where the internet becomes invisible and intelligence becomes ambient. We won’t “search” the way we used to. We’ll simply ask. And the answers will find us.
Voice+vision search is not the future of search. It’s the first interface of the post-search era where the best answer wins, the best entity is chosen, and the most structured brand becomes the default recommendation.
The technology is live. The capital is deployed. The behavior is forming.
The only question left is whether you’re building for the search box... or for the world itself?
Signing out,
Pankaj & Vaishali